.jpg?width=60%25)
Separating classes by minimizing misclassification rate. The circles around points illustrate the nearest neighbor delta-cover.
We present a new exemplar-based clustering algorithm, Pairwise Exemplar Clustering (PEC), that improves the performance of existing exemplar-based clustering method such as Affinity Propagation [Frey07]. PEC models arbitrary underlying distribution of the data by non-parametric kernel density estimation. We propose a new measure for separating different classes by minimizing the misclassification rate of the nearest neighbor classifier. The broadly used kernel form of cut turns out to be a special case of our new measure. We build the objective function based on this new measure and optimize it by maximizing a posterior in a Pariwise Markov Random Field. We also design an efficient algorithm for message computation to reduce the time complexity from O(N^2) to O(N). Experiments on synthetic and real datasets demonstrate the effectiveness of our method.
|
|
Separating classes by minimizing misclassification rate. The circles around points illustrate the nearest neighbor delta-cover. |
  |
|
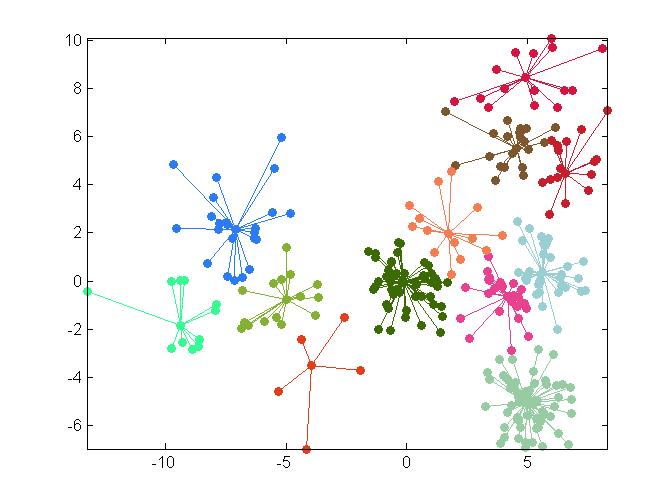
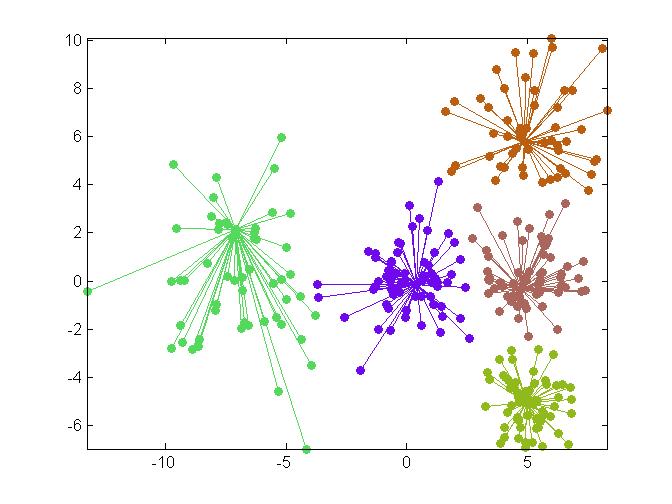
Clustering result on 300 pioints whose distribution is a mixture of 5 gaussians with different scales. Each data point is linked to its cluster exemplar (the representative of the cluster). Left: result by Affinity Propagation [Frey07]. Right: result by our method. |
|
|
 |
|
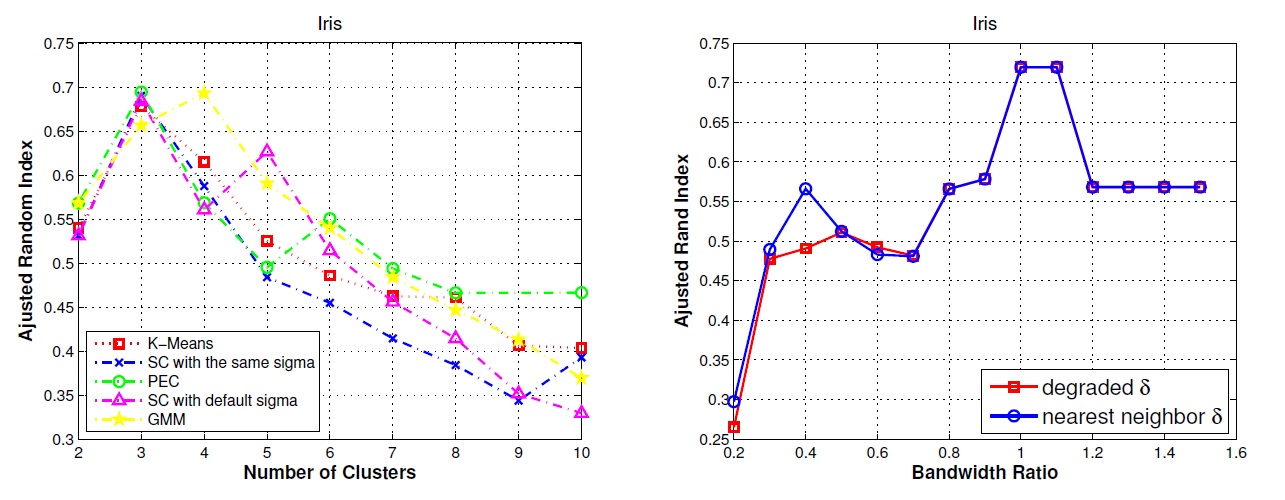
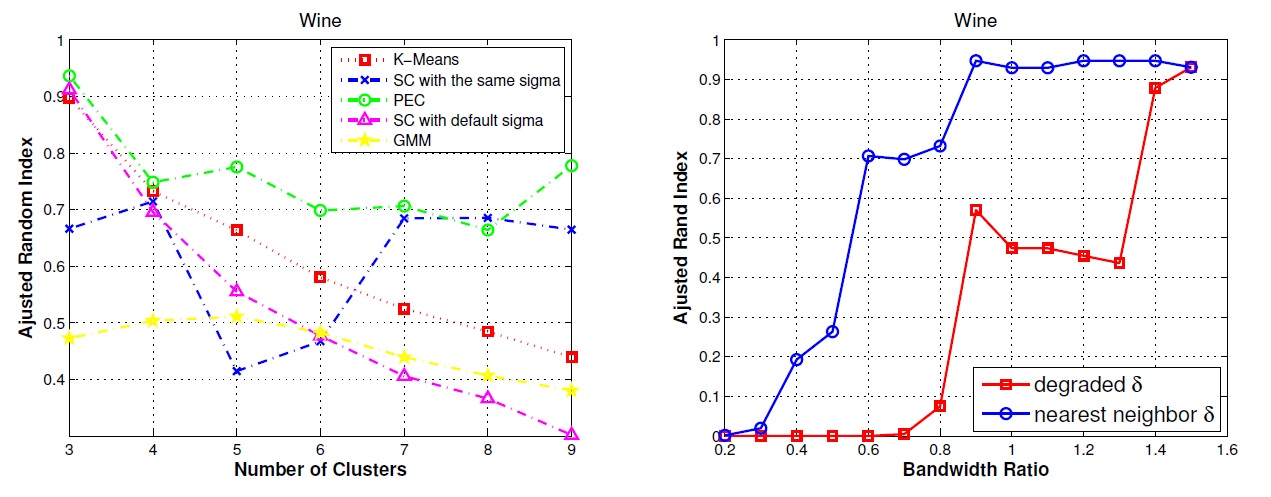
Repeat the simulation 10 times, and we compare PEC to K-means, Spectral Clustering [Ng01], Gaussian Mixture Model (GMM), and Affinity Propagation (AP). Avg. ARI is the average ARI (Ajusted Rand Index), SD stands for standard deviation of the ARI, and AC is the average number of clusters by model selection. |
SC stands for Spectral Clustering, and nearest neighbor delta-cover is our new separability measure for different classes, and it is compared to the traditional kernel similarities which corresponds to the degraded delta-cover in our formulation (a degraded special case of our formulation).
 |
|
Clustering on UCI Iris data set |
 |
|
Clustering on UCI Wine data set |
 |
|
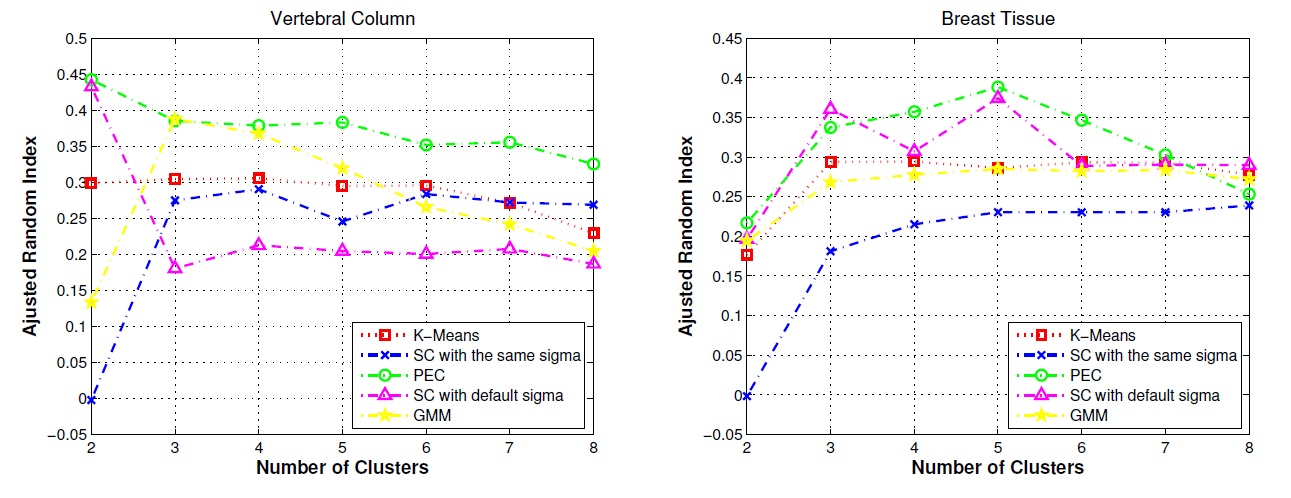
Clustering on UCI Vertebral Column and Breast Tissue data sets |
[Frey07] Frey, B. J., and Dueck, D. 2007. Clustering by passing messages between data points. Science 315:972-977.
[Ng01] Ng, A. Y.; Jordan, M. I.; and Weiss, Y. 2001. On spectral clustering: Analysis and an algorithm. In NIPS, 849-856.